csv-Tabellenkalkulation im Terminal mit bash und (g)awk

Querverweise
- Generierung formatierter Excel-Dateien aus erweiterten csv-Dateien mit Ruby
- Wandlung kommaseparierter in semikolonseparierte csv-Dateien mit Flex
- Pivotierung von csv-Dateien
- Wechselseitige Konvertierung von csv- und sc-Dateien
- Hier geht's zu den bash-(g)awk-Scripts
Appetizer
2 Aufbereitungsvarianten derselben csv-Datei zu Darstellung oder Editierung (hier mit vim)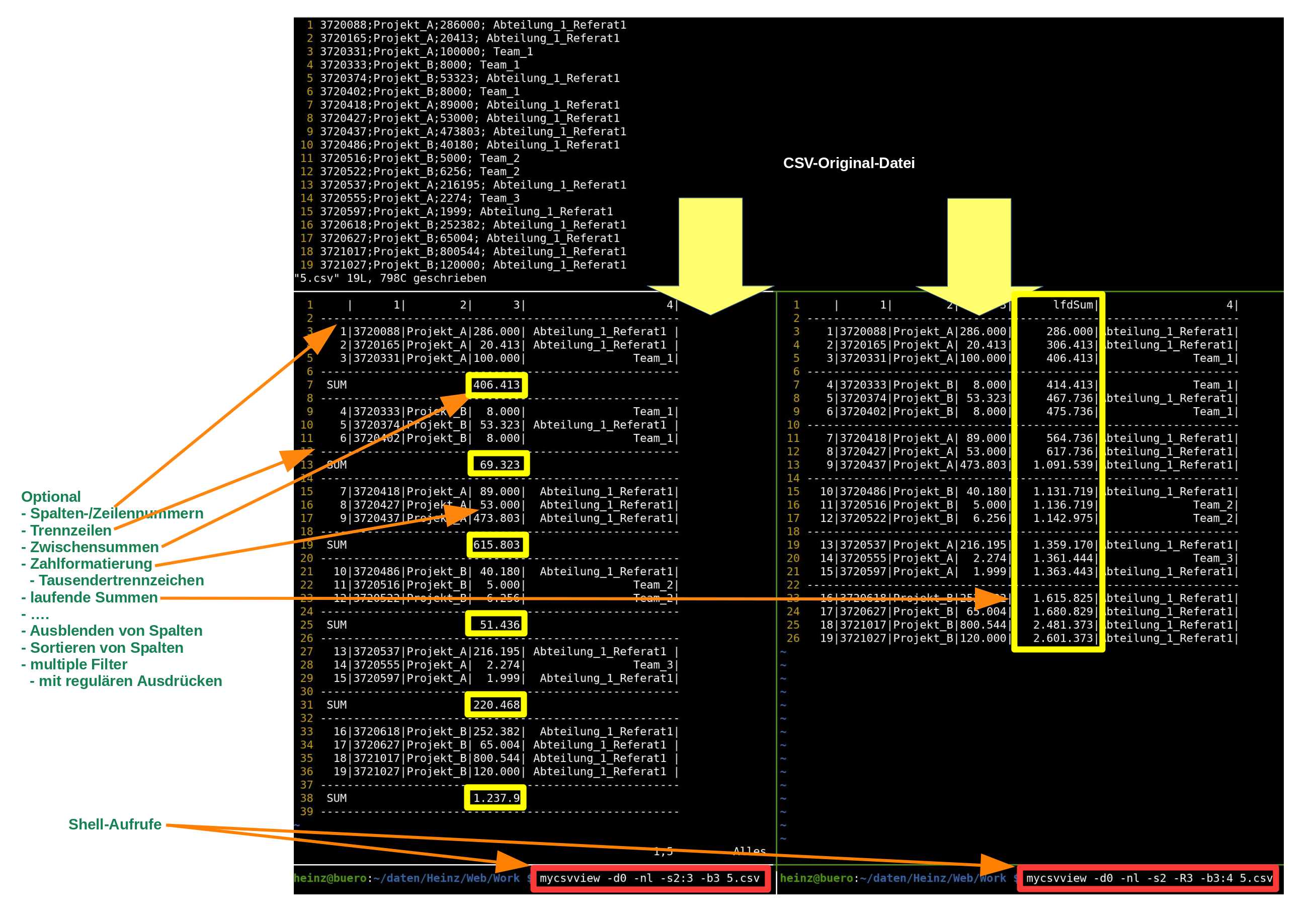
Warum CSV nicht nur im Terminal die bessere Tabellenkalkulation ist
Die Anzahl Excel--Dateien, aufgrund derer Unternehmen jeglicher Größenordnung täglich wichtigste Entscheidungen treffen, dürfte bei mehreren 100 Millionen liegen. Damit hängen große Teile der Weltwirtschaft an einem System, welches gegen die wichtigsten Paradigmen der IT verstößt- Vermengung von Logik, Code und Darstellung
- Formeln haben für einfache Logiken (etwa 2 kombinierte wenn-dann-Beziehungen) nicht nur eine kaum mehr leserliche Komplexität, sondern werden nicht einmal wiederverwendet, vielmehr genau so oft (falsch oder richtig selbst oder automatisch) kopiert, wie ingesamt benötigt.
- Die Formatierung von Feldern ist nicht nur abhängig von der Sprachversion, sondern beeinflusst die Logik UND wird dabei oft genug von gleich mehreren Bearbeitern für jedes Feld (falsch oder richtig) manuell festgelegt oder kopiert. Hinzu kommen jede Menge subtile Schreib- und Formatierungsfehler in bereits mittelgroßen, mehrfach zwischen Bearbeitern kopierten Dateien.
- Auch deswegen sind Mitarbeiter viel mehr mit Formatierung und "hübsch machen" von Dateien beschäftigt als fachlichem Inhalt und Korrektheit
- Während die Tabellenkalkulation für Maus-Bedienung eines Menschen ausgelegt ist, entstammen die Datenquellen zumeist Unternehmens-Backends und müssen erst (oft genug als CSV) aufbereitet und eingelesen werden. Gleichzeitig ist auch der erneute Export
sehr fehleranfällig
- Formatierungs- und Schreibfehler manueller Zwischenbearbeitung im GUI
- Versionsabweichungen des Programmes und geänderte Sprach- und Darstellungseinstellungen bei Ketten von Bearbeitern
- Zahldarstellungen (Tausendertrenner, Dezimalkennung, Ganz- oder Gleitkommazahl)
- hierbei interne Verarbeitung meist englisch, Darstellung deutsch
- viele verschiedene Datumsformatierungen zuzüglich derer Abkürzungen (Jahreszahl)
- Text-, Währungs-, Zahl-, oder Datumsbedeutung eines Feldes
- Zahldarstellungen (Tausendertrenner, Dezimalkennung, Ganz- oder Gleitkommazahl)
- blind übernommene Exporteinstellungen (Feldtrenner und Textkennzeichen uneinheitlich, manuell eingefügte Zeilenumbrüche in Text-Feldern)
- inkompatible Zeichensätze (ISO-8559-1, UTF-8, ASCII, Umlaute, Sonderzeichen, ...)
- dieselben Abläufe (etwa entscheidungsrelevante Filtereinstellungen oder Pivotierungen) müssen immer wieder fehleranfällig für jede Datei (oft genug auch innerhalb derselben) manuell wiederholt werden
Möchte man wesentliche Aspekte des vorigen in Unternehmen nicht ohnehin als absolute No-No einstufen, ergeben sich folgende "Vorteile" reiner CSV-Verarbeitung im Terminal:
- nicht wahrnehmbare Start-/Ladezeit bei minimalem Ressourcenverbrauch
- hohe Verarbeitungs- und Bediengeschwindigkeit (keine Mausbedienung, kein beständiger Oberflächen-Update)
- rein maschinelle Formatierung (immer korrekt, keine Redundanz, keine oder eindeutig und schnell erkennbare Fehler)
- Nettofenster == Bruttofenster (keine Bedienleisten oder Kacheln)
- Funktionalität "at your hands" (keine verschachtelten Menüs mit versteckten Funktionen)
- Automatisierung über sämtliche Datenquellen, Sprachen, Standards und Dateien kombinierbar (kein Scripting nur innerhalb derselben Datei wie etwa mit VBA)
- damit nahtlose Einbettung in die Workflows von Unternehmensbackends und -servern (nicht nur auf Anwender-Desktop verfügbar)
- strikte Trennung von Darstellung, Datenmodell und Logik (bestmögliche Fehlerfreiheit, keine Ablenkung vom Wesentlichen)
- Code/Funktionalität nur an einer einzigen Stelle (keine Proliferation redundanter Formeln in jeder Zelle)
- einfache Fehlersuche ohne Myriaden kopierter/automatisch eingefügter Formeln
- Klare Logik einer Programmiersprache (keine kryptische-unleserliche Syntax bereits einfacher Anweisungsketten ("wenn, dann (wenn, dann, sonst ...), sonst ...")
- Konzentration auf Fachlichkeit statt Formatierung(sprobleme (verstärkt bei mehreren Bearbeitern)
- Code/Funktionalität nur an einer einzigen Stelle (keine Proliferation redundanter Formeln in jeder Zelle)
- auch multiple Filter- und Pivotanweisungen sind durch Kommandozeile irrtumsfrei gespeichert, damit dokumentiert und identisch (auch in weiteren Dateien) beliebig wiederholbar (kein immer neues und fehleranfälliges "manuelles Zusammenklicken")
- Unabhängigkeit von Betriebssystem und Desktop (unter Windows etwa mit cygwin oder dem Linux-Subsystem)
- voller Funktionsumfang auch im Fernzugriff per ssh
- allgemeines, von jedem Programm und jedem Betriebssystem verstandenes Austauschformat
- Funktionsumfang beliebig erweiter- und damit anpassbar (keine Abhängigkeit von kommerziellen Produkten/Versionen/Lizenzen)
- Schönheit und Klarheit des Minimalen; Reduktion auf Inhalt und Funktion
- Beliebige Serialisierung/Kombination von Verarbeitungsketten/Workflows durch Pipes
csv-Verarbeitung für den Desktop
Diesem Zweck dient die folgende Sammlung an bash-(g)awk-Scripts, welche, jeweils auf der Kommandozeile mit Optionen aufgerufen, CSV-Datein für typische Fragestellungen verarbeiten.Präambel
- Alle Scripte haben eine Option -h, um die Bedienung zu erläutern
- Aus- und Eingaben sind beliebig verknüpfbar
- Festzulegen ist, ob ein '.' der Zahldarstellung in csv-Quellen als Dezimalpunkt oder Tausendertrennzeichen zu interpretieren ist
- Als Spaltentrennzeichen für csv-Dateien wird durchgehend ';' angenommen
- Alle Programme sind bash-Scripts mit implizitem gawk-Script
- Da csv-Dateien in den meisten Fällen aus Excel exportiert worden sein dürften, werden erstere konvertiert DOS => Unix, Zeichensaetze, Umlautersetzung ...
- Es gibt ein Ruby-Programm des Autors zur Wandlung ausgewählter Sheets aus Excel-Dateien in ';'-separierte csv-Darstellungen
- Einige Scripts bieten eine Option -n, um Konvertierung zu verhindern. In diesem Fall muss die Nutzdatei bereits als UTF-8 oder ASCII-Datei im Unix-Format vorliegen
- Zahlformate werden bei Berechnungen intern in englische Darstellung gewandelt; mit der Option -d kann festgelegt werden, ob ';' oder ',' vor 3 Ziffern als Dezimalpunkt oder Tausendertrenner zu interpretieren ist
- alle anderen Fälle können automatisch bestimmt werden
- Zu Beginn von common können Standardpfade festgelegt werden, welche als Default in das Home-Verzeichnis verweisen
- Syntax und Verwendung aller Scripts können mit <script> -h angezeigt oder direkt der jeweiligen Funktion usage() im Quellcode entnommen werden
- Dabei dienen vermeintliche Langformen von (ausschließlich Kurz-)Optionen lediglich der Erläuterung (Beispiel: -i(nfile))
- Alle Scripte verwenden die bash- und gawk--Includes common und commonroutines.awk des Downloadbereiches
- Für Option -F von mycsvfilter wird in Verzeichnis /usr/local/bin außerdem die Filter-Konfigurationsdatei filter.config erwartet. Ein Beispiel findet sich ebenfalls im Downloadbereich
- mycsvview und mycsvcalc verwenden selbst mycsvfilter und haben daher mit letzterem gleichlautende Optionen
- mycsvview
- Formatierte Darstellung von csv-Dateien
- normierte Spaltenbreiten
- Spalten- und Zeilennummern
- Ausblenden von Spalten
- Formatierung von Zahlen (Tausendertrennzeichen)
- Kombiniertes Sortieren von Spalten; auf-/absteigend, numerisch oder alphabetisch
- Kombinierte Filterung von Spalten nach regulären Ausdrücken wie festen Werten (cf. mycsvfilter
- laufende Summen für beliebige Spalten
- automatische Trennzeilen anhand Ausprägungswechsel in einer definierten Spalte
- optional zusätzliche Bildung von Zwischensummen in beliebigen Spalten
- Formatierte Darstellung von csv-Dateien
- mycsvcalc
- Summation von Spalten optional mit kombinierter Vorfilterung beliebiger Spalten nach regulären Ausdrücken (cf. mycsvfilter)
- mycsvfilter
- Filterung von 1-n Zeilen anhand fester Werte oder regulärer awk-Ausdrücke
- optional können komplexe Filter unter /usr/local/bin/filter.config vordefiniert werden
- Ausblenden von Spalten
- Summation von Spalten
- parallele Ausgabe auf stdout (für Pipes und in (Default-)Ausgabedatei
- Filterung von 1-n Zeilen anhand fester Werte oder regulärer awk-Ausdrücke
- mycsvmerge
- Zusammenführung von Spalten je zweier csv-Dateien anhand zu definierender Schlüsselspalten beider Dateien
- Wahlweise Einfügen, Konkatenieren oder optionales oder zwingendes Überschreiben
- Vergleich festzulegender Wertespalten zweier csv-Dateien anhand ebenso festzulegender Schlüsselspalten
- Zusammenführung von Spalten je zweier csv-Dateien anhand zu definierender Schlüsselspalten beider Dateien
- mycsvedit
- Editierung von csv-Dateien in der Darstellung von mycsvview mit impliziter Rekonvertierung nach csv
- mycsvsort
- alphabetische oder numerische, auf- oder absteigende Sortierung der 1-n Spalten
Anwendungsbeispiel
Betrachten wir dazu 4 Tabellen eines Warensortiments, welche via Artikelnummer oder Artikelbeschreibung und Markt verknüpft, gefiltert, sortiert, kalkuliert und visuell aufbereitet werden sollenOriginale (Trennzeichen: ';')
- 1.csv: Artikelnummer, Filiale und deren Bestand
- 2.csv: Artikelnummer und Artikelbeschreibung
- 3.csv: Artikelnummer und verfügbares Zubehoer
- 4.csv: Artikelbeschreibung, Filiale und (nur) dort gültiger Preis

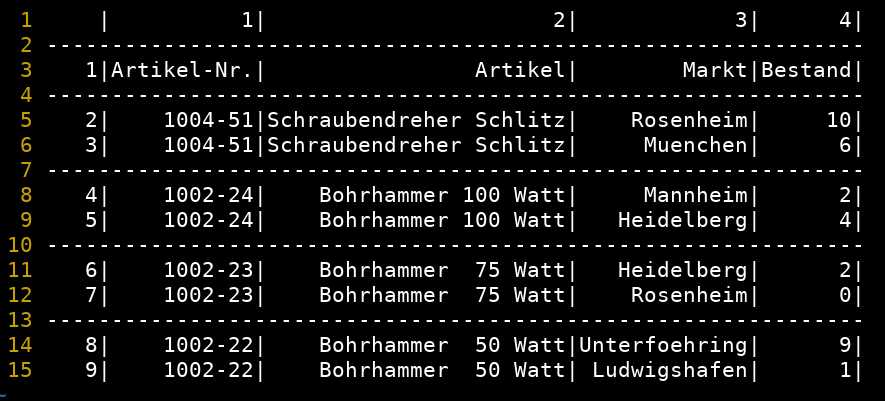
Formatierte Darstellung mit alternativ
- mycsvview -n -l -s 1 datei.csv
- nutzerfreundliche Darstellung mit optimierter Spaltenbreite, Spalten-, Zeilennummern und automatischen Trennzeilen (hier bei Ausprägungswechsel in Spalte 1)
- mycsvedit datei.csv
- Implizite Konvertierung für vim-Sitzung/Editierung in voriger Darstellung und automatische Rekonvertierung zu csv-Datei
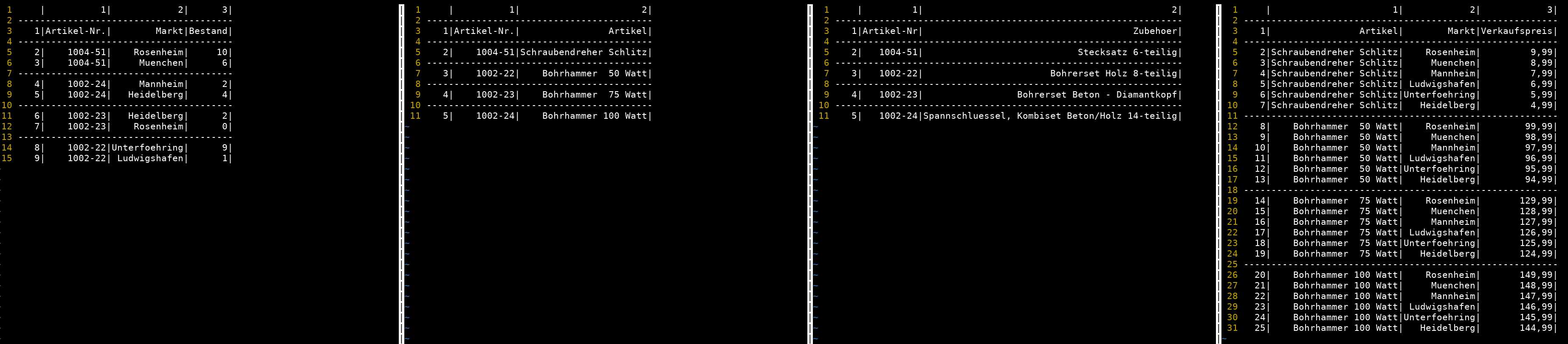
Verkettung mit Artikelbeschreibung
mycsvmerge -i 2.csv:1:2 -o 1.csv:1:1
mycsvview -nl -s1 1_merged.csv
- Einfuegen einer Spalte aus 2.csv in 1.csv anhand gemeinsamer Key-Spalte(n)
- Ergebnis ist (implizit) 1_merged.csv
#------------------------------------------------------------------------------- # Quelle # Datei 2 # Key: Spalte 1 (Artikelnummer) # Value: Spalte 2 (Artikelbeschreibung) # Ziel # Datei 1 # Key: Spalte 1 (Artikelnummer) # Zielspalte: nach Spalte 1 einfuegen #-------------------------------------------------------------------------------
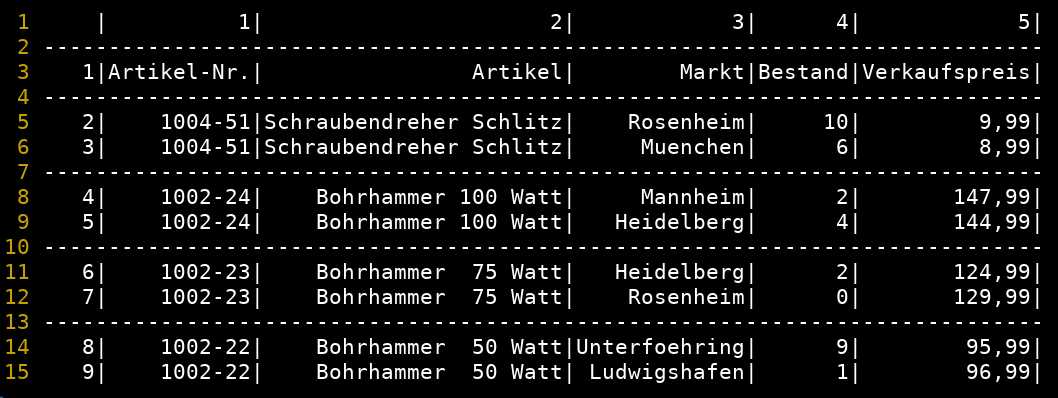
Weitere Verkettung mit Verkaufspreis in Abhängigkeit von Artikelbeschreibung und Filiale
mycsvmerge -i 4.csv:1u2:3 -o 1_merged.csv:2u3:hinten
mycsvview -nl -s1 1_merged.csv
- Einfügen des (auch von der Filiale abhängigen) Verkaufspreises aus 4.csv, diesmal anhand zweier Key-Spalten: Artikelbeschreibung und Markt !
- Keyspalten werden für Vergleichbarkeit implizit stets normiert (Leerzeichen, Umlaute, Sonderzeichen, ...)
- Angabe der Zielspalte in allgemeingültiger Forma als hinten
#------------------------------------------------------------------------------- # Quelle # Datei 4 # Key: Spalte 1 und Spalte 2 (Artikelbeschreibung und Markt) # Value: Spalte 3 (Verkaufspreis) # Ziel # veraenderte Datei 1 # Key: Spalte 2 und 3 (Artikelbeschreibung und Markt) # Zielspalte: hinten anfuegen #-------------------------------------------------------------------------------
Abschließende Verkettung mit erhältlichem Zubehör
mycsvmerge -i 3.csv:1:2 -o 1_merged.csv:1:2
mycsvview -nl -s1 1_merged.csv
- Einfügen optionalen Zubehörs aus Datei 3.csv hinter Artikelbeschreibung
#------------------------------------------------------------------------------- # Quelle # Datei 3 # Key: Spalte 1 (Artikelnummer) # Value: Spalte 2 (Zubehoer) # Ziel # veraenderte Datei 1 # Key: Spalte 1 (Artikelnummer) # Zielspalte: nach Spalte 2 einfuegen #-------------------------------------------------------------------------------

Verwerfen aller Zeilen ohne mehrteiliges Zubehör
mycsvfilter -f '3:.*teil.*' 1_merged.csv > 1_filtered.csv
mycsvview -nl -s1 1_filtered.csv
- Filterung nach mehrteiligem Zubehör in Spalte 3 mit Umlenkung nach 1_filtered.csv
- Filterung mit regulären Ausdrücken wie in gawk spezifiziert

Sortierung nach Artikelnummer
mycsvsort -k 1:4 1_filtered.csv > 1_sorted.csv
mycsvview -nl -s1 1_sorted.csv
- Sortierung nach Spalte 1 (Artikelnummer) und Spalte 4 (Filiale) mit Umlenkung nach 1_sorted.csv

Summierung aller Filialbestaende
mycsvcalc -c 5:1:1000 -t "Bestandssumme" 1_sorted.csv
- Kalkulation des Bestandes (Spalte 5 von Zeile 1 bis zu hypothetischer Zeile 1000)
- intern: implizite Wandlung von Zahlformaten in englische Darstellung

Script-Suite
... und hier die Werkzeuge ...mycsvfilter
mycsvsort
mycsvcalc
mycsvmerge
mycsvview
mycsvedit
Impressum und Datenschutzerklärung