Scannen grosser Datenmengen auf der Linux-Kommandozeile
Meine 2009 angeschafften Fujitsu fi-5110EOX2 und Fujitsu 510M ...

Update: Nach Austausch je 2 kleiner Zuführungsrollen funktionieren die Fujitsu fi-5110EOX2/510M auch deutlich im zweiten Jahrzehnt reibungslos. Bis die kleinen Rollen eintrafen, hatte ich jedoch aus "Mann-im-Baumarkt-Syndrom" bereits ein aktuelles Scannermodell Fujitsu fi-7160

geordert und es war ziemlich langweilig zu sehen, dass auch dieses mit den Scripts myscan/myscangui des Downloadbereiches aus dem Stand, also ohne jeden jeden Anpassungsaufwand im Code Dokumente wortwörtlich "hindurchschoss". Ein bißchen beneidet man Windows-/Mac-User ob der notwendigen Treiber- und Softwareinstallationen wie ständigen Aktualisierungen. Es bleibt unter GNU/Linux, einmal eingerichtet, über Jahrzehnte so aber auch wirklich gar nichts zu tun ;-).
Aber eine Kleinigkeit haben wir doch noch als Zusatz-Tipp:
- Unter /etc/saned./dll.conf alle Treiber außer fujitsu (aus)kommentieren => alle Fujitsu-Scanner werden dann in derselben Sekunde, in welcher der Scanbefehl abgeschickt wurde, angesteuert und der Scan (bzw. Hindurchschuss bei neuen Modellen, bitte von der "Mündung" wegbleiben) beginnt unmittelbar. Gleiches gilt natürlich auch für andere Hersteller-Treiber (z.B. plustek für Canon-Modelle
Vor Jahren also hatte ich mir 2 teure Dokumentenscanner (i.e. Scanner mit Stapeleinzug) für Windows und Mac
gekauft.
Zum Glück wurden seit WinXP und MacOS-Leopard vom Hersteller keine Treiber mehr angeboten, so dass ich
nun endlich gezwungen war, ein Script zu schreiben, mit welchem man beide Scanner unter Linux viel schneller und
komfortabler auf der Kommandozeile mit allen Parametern bedienen kann (der GUI-Zwang vorher hatte schon immer gestört ;-). Z.B. wurden meine Diplomarbeit und Dissertation auf dieser Homepage hierüber scanned.
Sofern also sane-utils, i.e. die Bibliothek für Scanner-Backends, imagemagick und ghostscript, sowie ein PDF-Viewer für die implizite Ergebnisanzeige (hier mupdf) installiert sind, generiert das Script myscan des Downloadbereiches sehr gut komprimierte Scans bis zu 999-seitiger Dokumente in der korrekten Reihenfolge (!).
Beispielsweise erzeugtmyscan -C -d -r 150 -o Meine_Fachzeitschrift
aus Hochglanzzeitschriften mit 150 Farbseiten etwa 30 MByte große Dateien sehr guter Bildqualität.
Mit der Defaulteinstellung -r 100 ergibt sich etwa für die Archivierung von Schriftstücken ein in der Praxis sehr guter Kompromiss hinreichender Darstellungsqualität bei minimalen Datenmengen. Am Beispiel der Hochglanzzeitschriften erhält man so ceteris paribus mit 20 MByte vergleichsweise sehr kleine PDFs mit guter Lesbarkeit.
Die Optionen des Beispieles beziehen sich auf die Scannermodelle- Fujitsu ScanSnap FI-5110EOX2 (Windows)
- Fujitsu ScanSnap S510M (Mac)
Wer wissen möchte, wie man für alle Arten von Endgeräten Duplex-Dokumentenscanner in einem Netzwerk über einen Raspberry Pi
 bereitstellt, erfährt das hier.
bereitstellt, erfährt das hier.Übersicht der Optionen ...
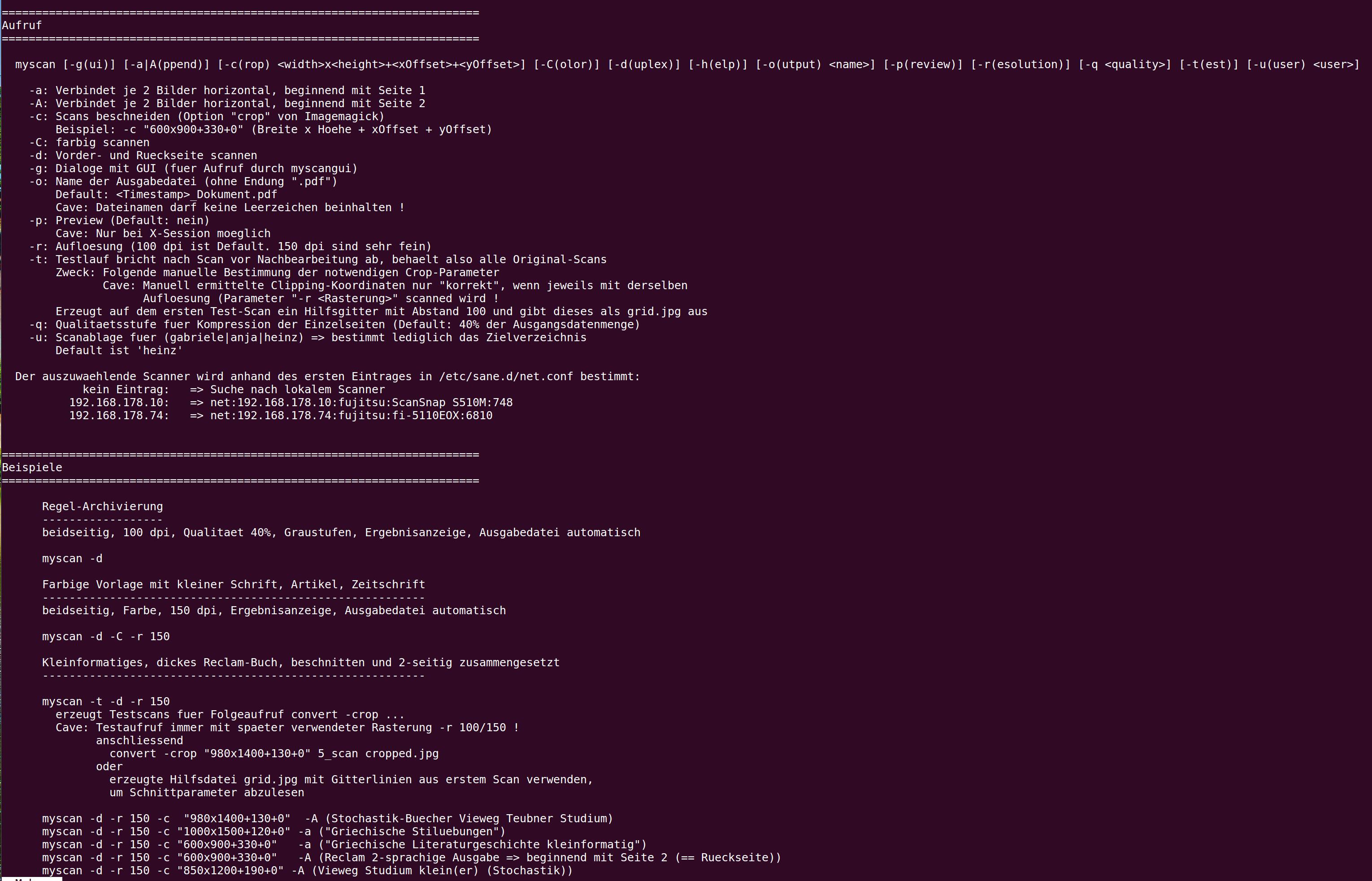
... ein Beispiel der mit myscan -t -d -r 150 erzeugten Datei grid.jpg, um die Schnittkanten fuer das Begrenzen und Aneinanderfügen von Buchseiten zu ermitteln ...
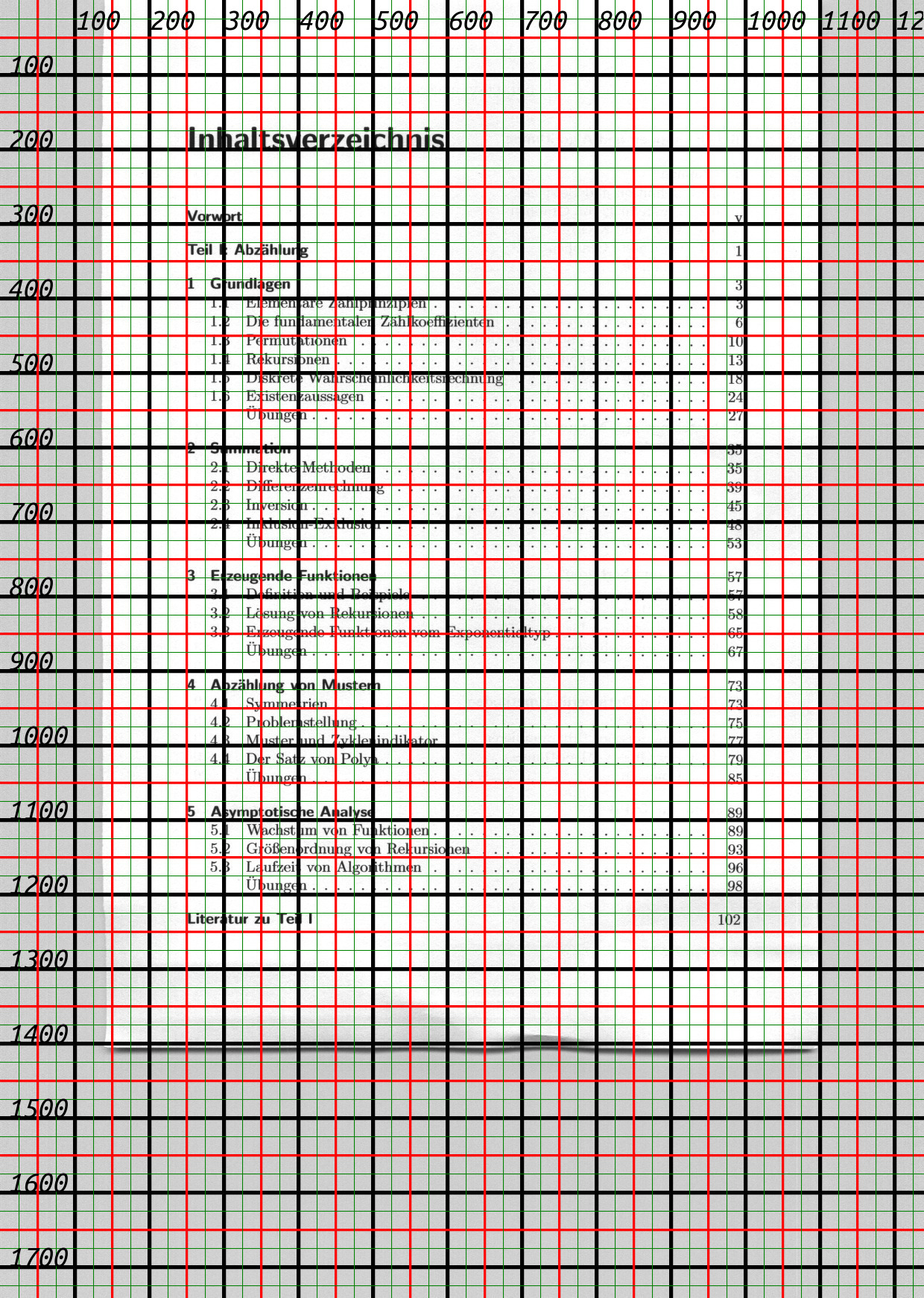
... und eine aus je 2 beschnittenen Seiten über den Aufruf myscan -d -r 150 -c "850x1200+190+0" -A -o Stochastik.pdf" zusammengefügte Doppelseite des anschließenden Buchscans mit den vorig bestimmten Parametern
Impressum und Datenschutzerklärung