Hotkeys (Tastatursteuerung)
| Befehl | Aktion |
|---|---|
| + | Vergrößerung aller Bilder |
| - | Verkleinerung aller Bilder |
Die meisten Skripte erwarten 3 Dateien an folgenden Orten
- /usr/local/bins (bins => "bin shared" => diese Bibliotheken sind für verschiedene Umgebungen identisch)
- /usr/local/bin
- commonspecific.awk (1 Dummy-Routine zu Kompatibilität mit anderen Umgebungen und realer Implementierung) Download
- inkludiert von commonroutines.awk
- commonspecific.awk (1 Dummy-Routine zu Kompatibilität mit anderen Umgebungen und realer Implementierung) Download
- set foldmethod=marker
- set foldmarker={{{{,}}}}
- myscript -h
myscan [-g(ui)]
....
....
Wichtigst: CSV-verarbeitende Skripte erwarten folgendes Format:
- Trennzeichen: Semikolon
- keine Hochkommata (Gänsefüßchen)
- CSV-Dateien mit Kommata als Trenn- und Hochkommata als Textkennzeichen, sowie Zeilenumbrüchen in Spalten können mit dem Lexer mycsv2csv in das vorige Format gewandelt werden.
- Zahlen dürfen keine Tausendertrennzeichen, jedoch einen für alle Zahlen der jeweiligen Datei einheitlichen deutschen oder englischen Dezimaltrenner haben.
- cf. hierzu mycsvanalyze und mycsvconvert.
mycsvmerge
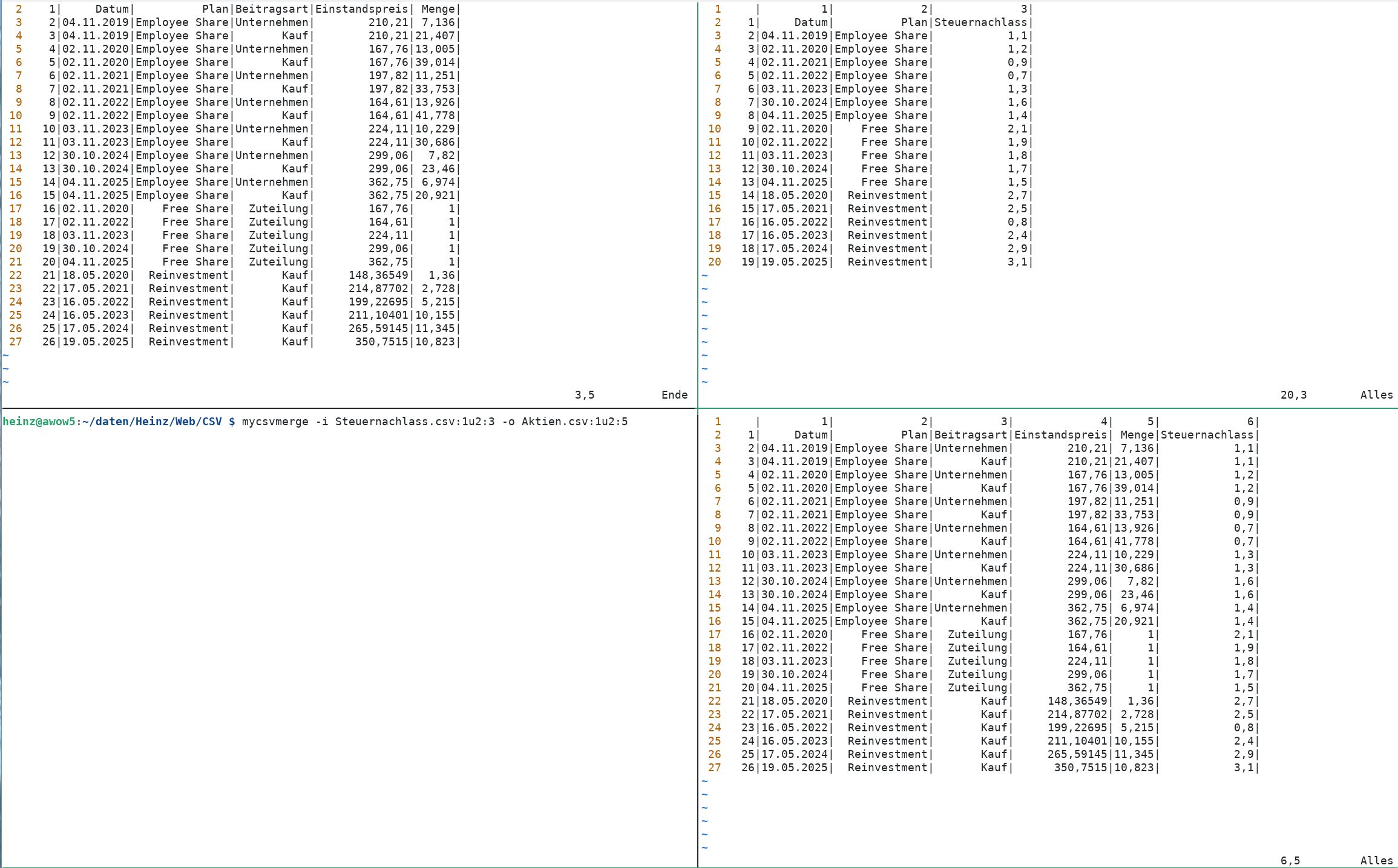
Verschmelzung der Spalte "Steuernachlass" aus Steuernachlass.csv mit Aktien.csv zu Aktien_merged.csv anhand der Kriterien der jeweils ersten beiden Spalten "Datum" und "Plan".
Erzeugt durch
- links oben
- mycsvview Aktien.csv
- vim pretty
- rechts oben
- mycsvview Steuernachlass.csv
- vim pretty
- rechts unten
- mycsvmerge -i Steuernachlass.csv:1u2:3 -o Aktien.csv:1u2:5
- mycsvview Aktien_merged.csv
- vim pretty
Verschmelzung oder Vergleich zweier csv-Dateien anhand Kriterienspalten
/usr/local/bins/mycsvmerge -i(nsert) <csv1>:<keycol(s)>:<valuecol(s)> -o(ut) <csv2>:<keycol(s)>:<targetColFile2> [-c(oncatenate|-r(eplace)|-R(eplaceforce)] [-n(oconvert)] [<outfile>]
/usr/local/bins/mycsvmerge -i(nsert) <csv1>:<keycol(s)>:<valuecol(s)> -o(ut) <csv2>:<keycol(s)>:<valuecol(s)> -C(ompare) [-m(atchonly] [-n(oconvert] [<outfile>]
Cave: Option -c => concatenate (bei merge)
Option -C => compare (anstelle merge)
Cave: Nicht in Datei 2 vorhandene Keys aus Datei 1 (und umgekehrt) werden auf stderr ausgegeben (ggf. umleiten)
Funktion 1: Merge
- mehrere key-Spalten in Datei 1 und Datei 2 (werden zusammengefasst)
- mehrere value-Spalten in Datei 1 (werden zusammengefasst)
- eine Zielspalte in Datei 2
- einfuegen dahinter oder Konkatenierung mit dieser
- Ausgabe der erweiterten Datei 2 in Datei 2_merged.csv oder <outfile>
/usr/local/bins/mycsvmerge -i(nsert) <csv1>:<keycol(s)>:<valuecol(s)> -o(ut) <csv2>:<keycol(s)>:<targetColFile2> [-c(oncatenate|-r(eplace)|-R(eplaceforce)] [-n(oconvert)]
-n: Keine Konvertierung (Booster auf eigene Gefahr !)
Fuegt die Werte aus Spalten der ersten hinter oder in die Spalte einer zweiten csv-Datei ein.
<keycol(s)> ist dabei entweder die (bezueglich Auspraegungen) gemeinsame Schluessel-Spalte beider Dateien fuer
die Zuordnung der Werte aus <valuecol(s)> oder ein Ausdruck fuer mehrere jeweils gemeinsame Schluessel-Spalten der Form
<Zahl>u(nd)<Zahl>u(nd)<Zahl>...
Ebenso bezeichnet <valuecol(s)> entweder eine einzige oder mehrere Spalten <Zahl>u(nd)<Zahl>
Bei Option -c wird die Spalte mit der Zielspalte konkateniert, anderfalls dahinter eingefuegt
Bei Option -r wird die Spalte in die Zielspalte eingefuegt und ueberschreibt ggf. dortige Leer-Werte
Bei Option -R werden im Unterschied zu -r auch bestehende Werte der Zielspalte ueberschrieben
Convenience:
Ist die Zielspalte "hinten", wird hinter der letzten Spalte in csv2 eingefuegt.
Ist die Zielspalte "vorne", wird vor der ersten Spalte in csv2 eingefuegt.
Cave: Letzeres ist die einzige Moeglichkeit hierzu da '0' in awk $0 entspricht und alle Spalten referenziert
Beispiel:
/usr/local/bins/mycsvmerge -i Steinbruch.csv:1:2 -o Zieldatei.csv:1:5 -c
Key: jeweils Spalte 1
Value: Spalte 2 in erster Datei
Target: Spalte 5 in zweiter Datei (Konkatenierung)
Bei alternativer Option -r wuerde Spalte 5 ueberschrieben
/usr/local/bins/mycsvmerge -i Steinbruch.csv:1u3:2 -o Zieldatei.csv:2u4:5
Key: Spalten 1 und 3 in erster und 2 und 4 in zweiter Datei
Einfuegen der Spalte 2 der ersten Datei nach Spalte 5 der zweiten Datei (keine Konkatenierung)
/usr/local/bins/mycsvmerge -i Steinbruch.csv:1u3u9:2u4u7 -o Zieldatei.csv:2u3u4:vorne
Key: Spalten 1,3,9 in erster und 2,3,4 in zweiter Datei
Einfuegen der Spalten 2,4,7 der ersten Datei vor erster Spalte der zweiten Datei (implizit/logisch keine Konkatenierung)
/usr/local/bins/mycsvmerge -i Steinbruch.csv:1u3u9:2u4u7 -o Zieldatei.csv:2u3u4:hinten
dito, jedoch automatische Bestimmung der Zielspalte
Cave: Sofern keine Ausgabedatei angegeben war, ist Ausgabedatei ist immer *_merged.csv; selbst wenn die Eingabedatei bereits "merged" war ...
Besonderheit: Ist die Value-Spalte aus Datei 1 '999' wird in Datei 2 hinter (oder in) deren Zielspalte nur ausgegeben, ob
die Key-Kombination in Datei 1 vorhanden war.
Funktion 2: Comparison (Option -C)
- mehrere Key-Spalten in Datei 1 und Datei 2 (werden zusammengefasst)
- mehrere Value-Spalten in Datei 1 und Datei 2 (werden NICHT zusammengefallst, sondern getrennt betrachtet)
- Markierung fehlender oder Einfuegen abweichender Werte genau hinter die jeweilige value-Spalte in Datei 2
- Ausgabe in diff.csv
Cave: Nur key- und value-Spalten beider Dateien werden ausgegeben
/usr/local/bins/mycsvmerge -i(nsert) <csv1>:<keycol(s)>:<valuecol(s)> -o(ut) <csv2>:<keycol(s)>:<valuecol(s)> -C(ompare) [-m(atchonly] [-n(oconvert]
-C: Unterschied zu Funktion 1 => compare anstelle merge
-m: Ausgabe von 'match' bei Uebereinstimmung, sonst des abweichenden Wertes bei Daten aus Datei 1
Cave: Fuer Match werden Werte normiert
Beispiel
/usr/local/bins/mycsvmerge -i Referenz.csv:1u2u3:4u5u6 -o Pruefling.csv:2u1u3:5u6u7 -C
Abhängigkeiten
- gawk
Download
mycsvmergeImpressum